VVC based JND dataset
We establish a just noticeable distortion (JND) dataset based on the next generation video coding standard Versatile Video Coding (VVC). The dataset consists of 202 images which cover a wide range of content with resolution 1920×1080. Each image is encoded by VTM 5.0 intra coding with the quantization parameter (QP) ranging from 13 to 51. The details regarding dataset construction, subjective testing and data post-processing are described in this paper. Finally, the significance of the dataset towards future video coding re- search is envisioned. All source images as well as the testing data have been made available to the public.
Readme and download link
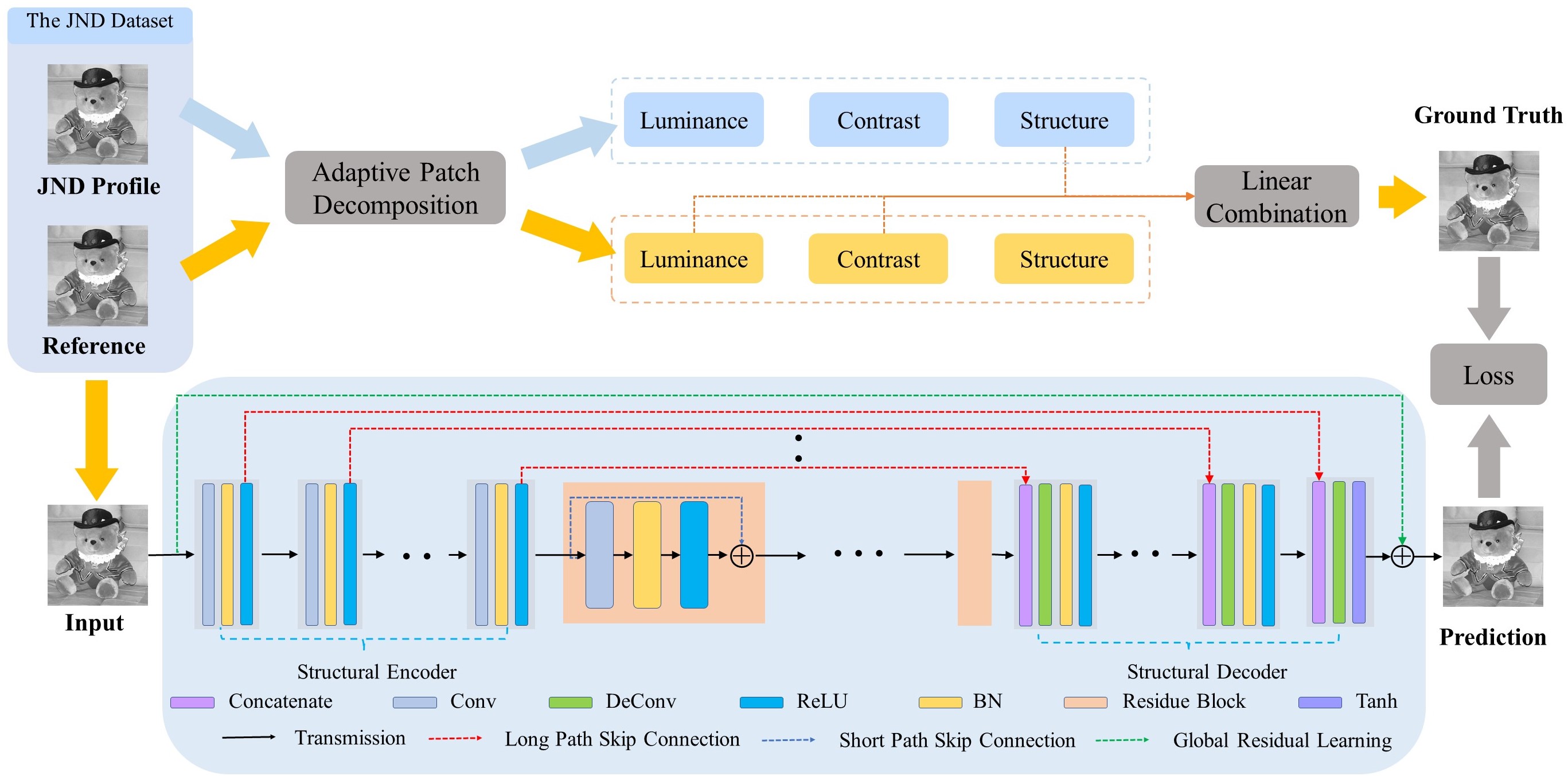
Patch-wise structural visibility learning model
we propose an effective approach to infer the just noticeable distortion (JND) profile based on patch- level structural visibility learning. Instead of pixel-level JND profile estimation, the image patch, which is regarded as the basic processing unit to better correlate with the human perception, can be further decomposed into three conceptually independent components for visibility estimation. In particular, to incorporate the structural degradation into the patch-level JND model, a deep learning-based structural degradation estimation model is trained to approximate the masking of structural visibility. In order to facilitate the learning process, a JND dataset is further established, including 202 pristine images and 7878 distorted images generated by advanced compression algorithms based on the upcoming Versatile Video Coding (VVC) standard. Extensive experimental results further show the superiority of the proposed approach over the state-of-the-art.
Code and pre-trained model
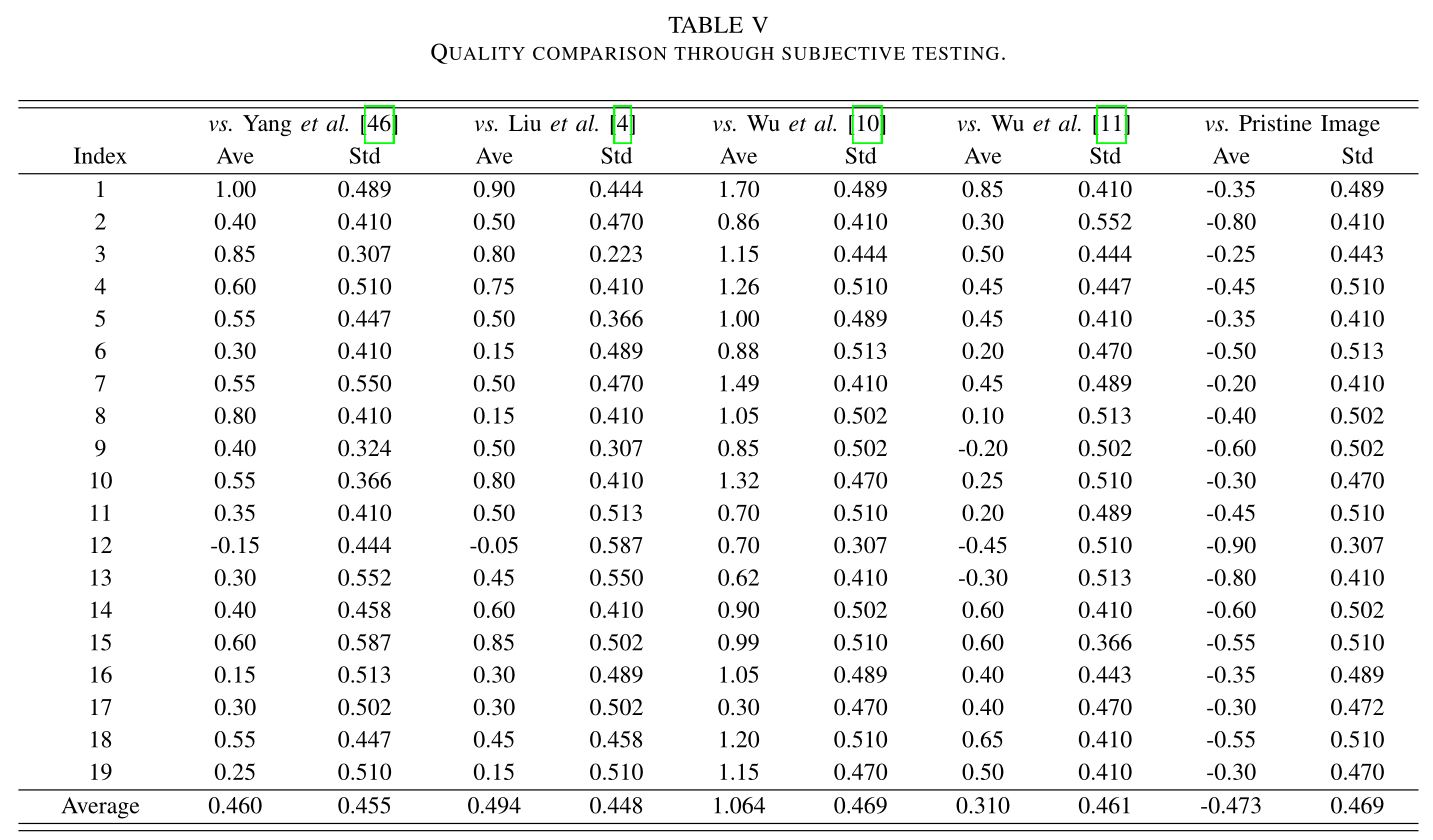
Experimental results
The subjective results exhibited in Table V have demonstrated that the proposed JND profile is superior to the conventional JND models. In general, there are several reasons behind this. First, the patch decomposition method provides an analytical representation of visual information by independent visual factors, which means that all the corresponding visibility maskings are involved in JND profile generation. This leads to the proposed JND model being able to tolerate more distortions and achieve better subjective performance while maintaining the same PSNR comparing with the conventional models. Second, estimating the JND profile at the patch-level instead of pixel/sub-band level aligns with the HVS mechanism. Third, the learning based approach improves the model’s applicability which means the proposed model is able to achieve favorable performances in patches of different contents. These lead to accurate JND estimation.
Refrence
[4] A. Liu, W. Lin, M. Paul, C. Deng, and F. Zhang, “Just noticeable difference for images with decomposition model for separating edge and textured regions,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 20, no. 11, pp. 1648–1652, 2010.
[10] J. Wu, G. Shi, W. Lin, A. Liu, and F. Qi, “Just noticeable difference estimation for images with free-energy principle,” IEEE Transactions on Multimedia, vol. 15, no. 7, pp. 1705–1710, 2013.
[11] J. Wu, L. Li, W. Dong, G. Shi, W. Lin, and Kuo. C-C Jay, “Enhanced just noticeable difference model for images with pattern complexity,”IEEE Transactions on Image Processing, vol. 26, no. 6, pp. 2682–2693,2017.
[46] X. Yang, W. Lin, Z. Lu, E. On, and S. Yao, “Motion-compensated residue preprocessing in video coding based on just-noticeable-distortion profile,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 15, no. 6, pp. 742–752, 2005.
Citation
If our work is useful for your job, please kindly cite the following papers:
[1] X. Shen, Z. Ni, W. Yang, X. Zhang, S. Wang and S. Kwong, "A JND Dataset Based on VVC Compressed Images," 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), London, United Kingdom, 2020, pp. 1-6, doi: 10.1109/ICMEW46912.2020.9105955.
[2] X. Shen, Z. Ni, W. Yang, X. Zhang, S. Wang and S. Kwong, "Just Noticeable Distortion Profile Inference: A Patch-level Structural Visibility Learning Approach," 2020 IEEE TIP.
Supplementary Material
This document is mainly about the supplementary experiments which are required in the response letter. Details and corresponding results are provided.
Supplementary Material
Contact
Thanks for your attention! If you have any suggestion or question, feel free to leave a message here or contact Xuelin Shen (xuelishen2-c@my.cityu.edu.hk).